
https://www.youtube.com/watch?v=22wlLy7hKP4
https://x.com/Saboo_Shubham_/status/1745811833129431439?s=20
LangChain
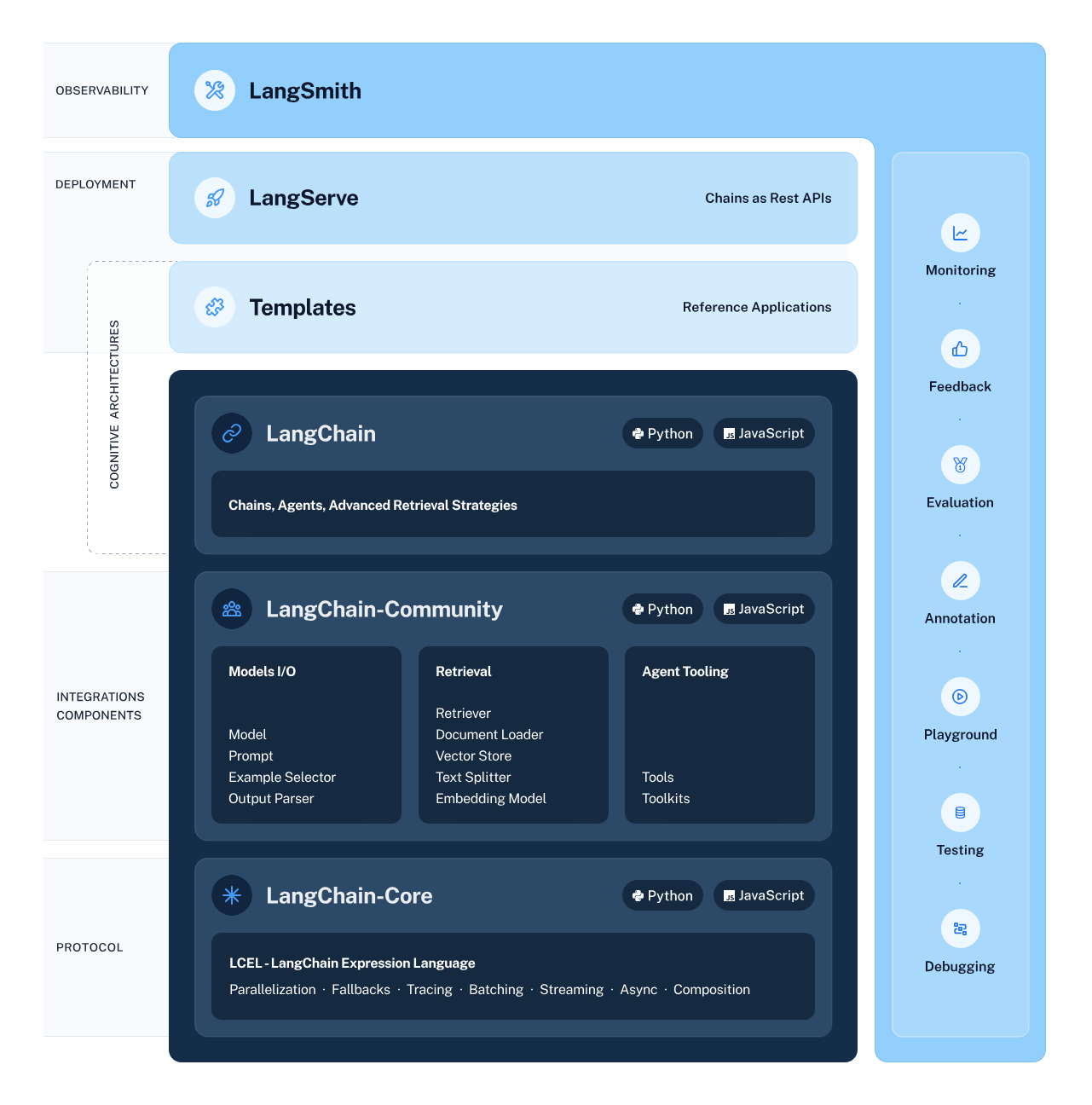
LangChain is a framework for developing applications powered by language models. It enables applications that:
- Are context-aware: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)
- Reason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)
This framework consists of several parts.
- LangChain Libraries: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.
- LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks.
- LangServe: A library for deploying LangChain chains as a REST API.
- LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
Create an EC2 Instance, with 64 Cores?
sudo apt install zip python3-pip
curl -fsSL https://get.docker.com -o get-docker.sh
sudo usermod -aG docker $USER
pip install jupyterlab
echo "export PATH=\$PATH:/home/ubuntu/.local/bin" >> ~/.bashrcSetup LocalAI with LangChain
mkdir models
mkdir images
.env
THREADS=64
GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}, {"url": "github:go-skynet/model-gallery/huggingface.yaml","name":"huggingface"}]
MODELS_PATH=/models
DEBUG=truemodels/embeddings.yaml
name: text-embedding-ada-002
backend: sentencetransformers
embeddings: true
parameters:
model: WhereIsAI/UAE-Large-V1Download Mixtral 8x7B
wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q3_K_M.ggufmodels/mixtral.yaml
name: mixtral
mmap: true
parameters:
model: mixtral-8x7b-instruct-v0.1.Q3_K_M.gguf
template:
chat: mixtral-chat
completion: mixtral-completion
context_size: 8192
f16: true
threads: 64models/mixtral-chat.tmpl
[INST] {{.Input}} [/INST]
models/mixtral-completion.tmpl
[INST] {{.Input}} [/INST]
docker-compose.yml
version: '3.6'
services:
api:
image: quay.io/go-skynet/local-ai:v2.5.1
tty: true # enable colorized logs
restart: always # should this be on-failure ?
ports:
- 8080:8080
env_file:
- .env
volumes:
- ./models:/models
- ./images/:/tmp/generated/images/
command: ["/usr/bin/local-ai" ]Start the Server!
docker compose up -dTest both models
curl http://localhost:8080/embeddings -X POST -H "Content-Type: application/json" -d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "mistral", "messages": [{"role": "user", "content": "How are you?"}], "temperature": 0.9 }'View logs
docker compose logs -f
You can also load Model from URL
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{
"url": "github:go-skynet/model-gallery/bert-embeddings.yaml",
"name": "text-embedding-ada-002"
}'this?
curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{
"url": "github:go-skynet/model-gallery/openllama-7b-open-instruct.yaml",
"name": "openllama-7b"
}'curl http://localhost:8080/models/apply -H "Content-Type: application/json" -d '{
"url": "github:go-skynet/model-gallery/llama2-7b-chat-gguf.yaml",
"name": "llama2-7b"
}'To Restart
docker compose restartLangChain
Basic example: prompt + model + output parser
pip install langchain langchain-openaiLCEL: LangChain Expression Language
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAIos.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="mixtral")output_parser = StrOutputParser()chain = prompt | model | output_parserThe | symbol is similar to a unix pipe operator, which chains together the different components feeds the output from one component as input into the next component.
In this chain the user input is passed to the prompt template, then the prompt template output is passed to the model, then the model output is passed to the output parser. Let’s take a look at each component individually to really understand what’s going on.
out = chain.invoke({"topic": "ice cream"})print(out)Why don't ice creams ever argue?
Because they always cool down before things heat up!(prompt | model).invoke({"topic": "ice cream"})AIMessage(content="Why don't ice creams ever argue?\n\nBecause they always cool down before things heat up!")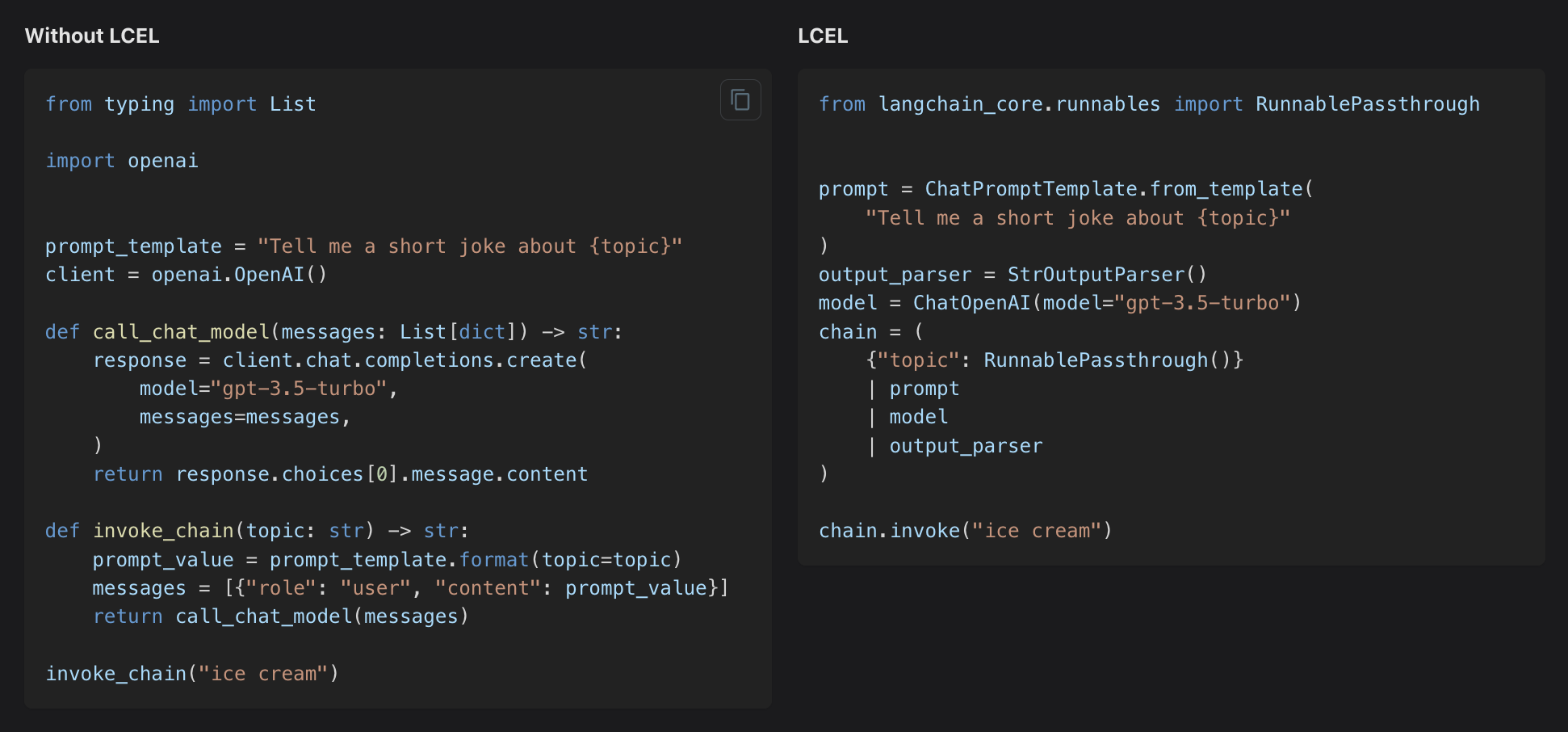
Function Calling
It’s in Beta for llama.cpp and localai, it only sort of works with models > 33B params
import openai
import json
import requests
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8080/v1", api_key="NONE")We will use the [tomorrow.io](http://tomorrow.io) api to get the weather of the location which the user wants
def get_current_weather(location, units="metric"):
"""Get the current weather in a given location"""
url = f"https://api.tomorrow.io/v4/weather/realtime?location={location.lower()}&units={units}&apikey=hZdpIwxHljGjU8UCsACtOQla3Ct4mZs2"
headers = {"accept": "application/json"}
response = requests.get(url, headers=headers).json()
weather_info = response['data']
return json.dumps(weather_info)This is how a function is defined for a LLM to understand what it does, it’s how OpenAI defined function calling
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. 'san francisco' or 'new york' or 'bengaluru' or 'toronro'",
},
"units": {"type": "string", "enum": ["metric", "imperial"]},
},
"required": ["location"],
},
}
]And this is what the user will ask
messages = [{"role": "user", "content": "What's the weather like in Delhi?"}]response = client.chat.completions.create(
model="mixtral",
messages=messages,
functions=functions,
function_call="auto", # auto is default, but we'll be explicit
)
response_message = response.choices[0].messageresponse_messageThe response says our LLM want’s to call the weather api
ChatCompletionMessage(content=None, role='assistant', function_call=FunctionCall(arguments='{"location":"Delhi","units":"metric"}', name='get_current_weather', function='get_current_weather'), tool_calls=None)if response_message.function_call:
available_functions = {
"get_current_weather": get_current_weather,
} # only one function in this example, but you can have multiple
function_name = response_message.function_call.name
fuction_to_call = available_functions[function_name]
function_args = json.loads(response_message.function_call.arguments)
function_response = fuction_to_call(
location=function_args.get("location"),
units=function_args.get("units"),
)function_response'{"time": "2024-01-23T15:45:00Z", "values": {"cloudBase": 0.38, "cloudCeiling": null, "cloudCover": 11, "dewPoint": 8.63, "freezingRainIntensity": 0, "humidity": 82, "precipitationProbability": 0, "pressureSurfaceLevel": 990.83, "rainIntensity": 0, "sleetIntensity": 0, "snowIntensity": 0, "temperature": 12.38, "temperatureApparent": 12.38, "uvHealthConcern": 0, "uvIndex": 0, "visibility": 14.65, "weatherCode": 1000, "windDirection": 44.69, "windGust": 2.31, "windSpeed": 1}}'if response_message.function_call:
messages.append(response_message) # extend conversation with assistant's reply
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
) # extend conversation with function response
second_response = client.chat.completions.create(
model="mixtral",
messages=messages,
) # get a new response from GPT where it can see the function responseprint(second_response.choices[0].message.content)LLM gets the response from the function and simply presents it better
Based on the provided data, the current weather in Delhi is:
* Temperature: 12.38 degrees Celsius
* Apparent temperature: 12.38 degrees Celsius
* Humidity: 82%
* Dew point: 8.63 degrees Celsius
* Pressure: 990.83 surface level
* Wind speed: 1 m/s
* Wind direction: 44.69 degrees
* Visibility: 14.65 km
* Cloud cover: 11%
* Cloud base: 0.38
* Cloud ceiling: null
* Precipitation probability: 0%
* Rain intensity: 0 mm/h
* Freezing rain intensity: 0 mm/h
* Sleet intensity: 0 mm/h
* Snow intensity: 0 mm/h
* UVI: 0
* Weather code: 1000 (clear sky)
I hope this information helps! Let me know if you have any other questions.Agents
We can think of agents as a way of providing "tools" for LLM (Language Model). Just like humans use a calculator to perform mathematical calculations or use Google searches to obtain information, agents allow LLMs to perform similar operations.
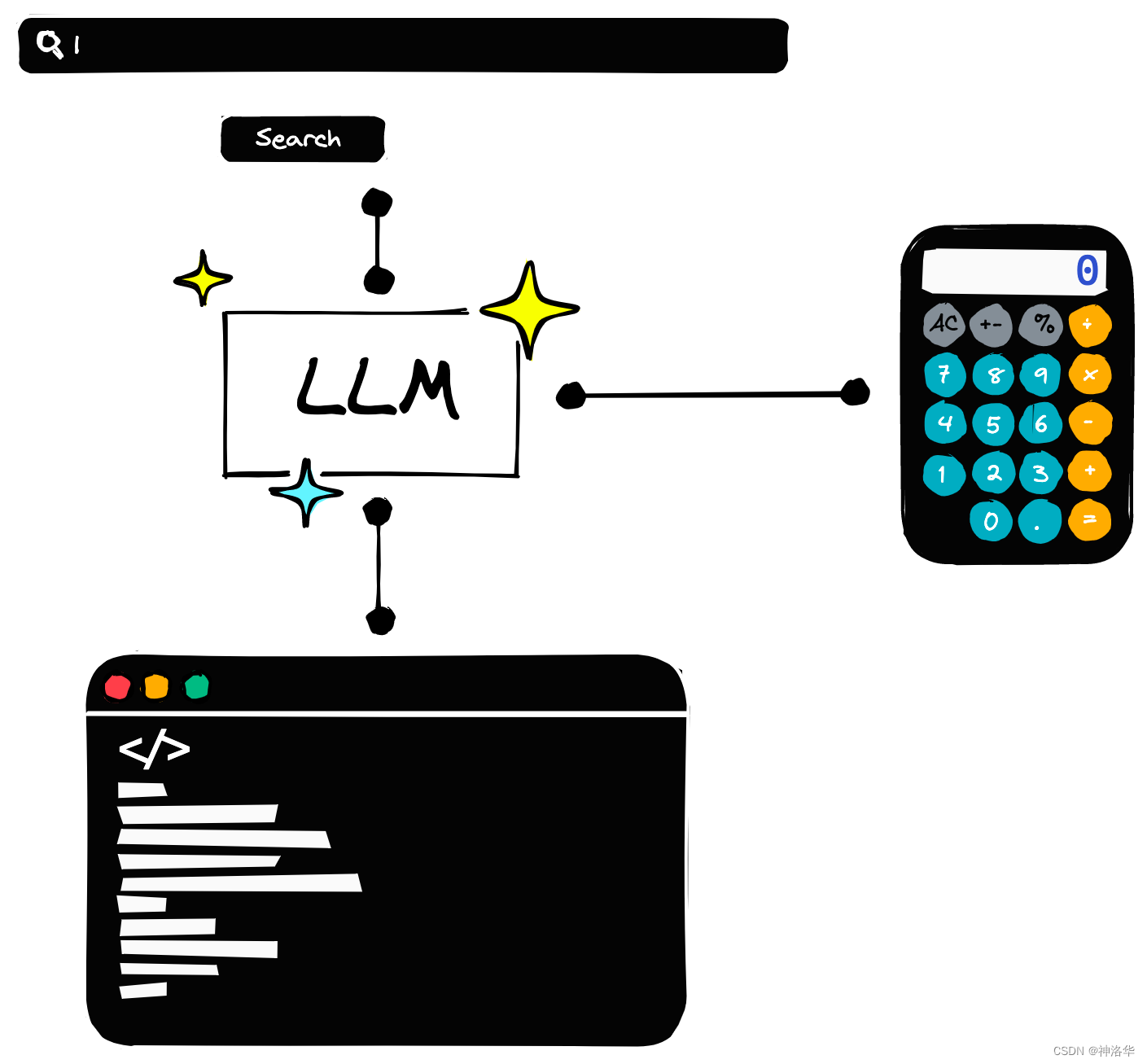
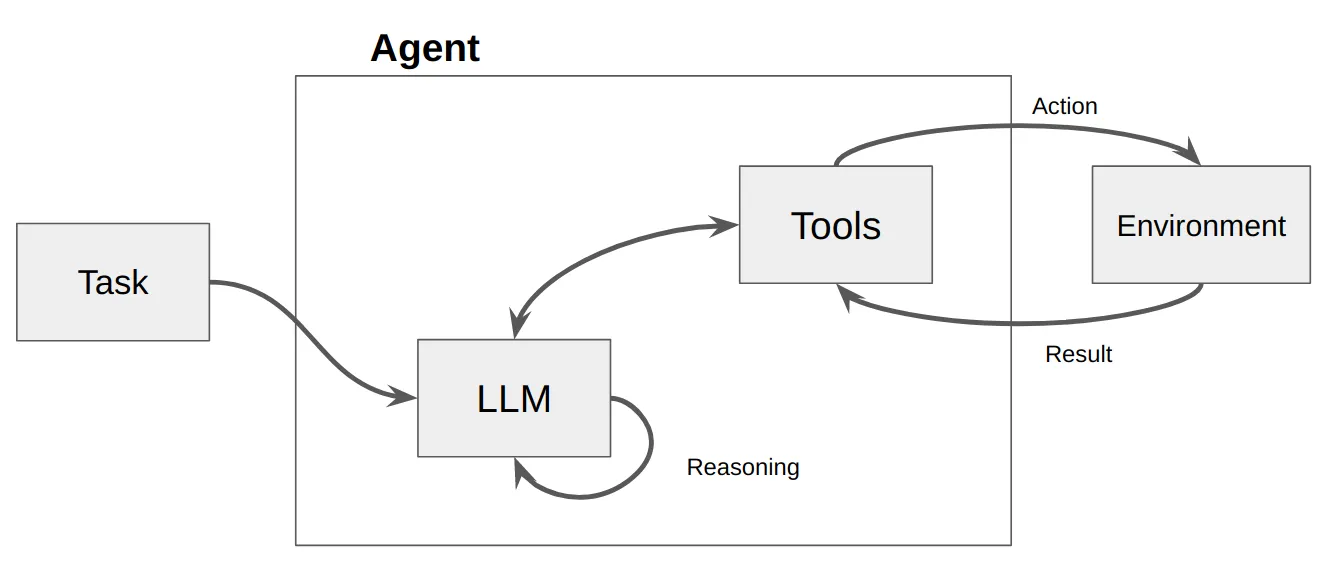
Agent Types
LangChain Hub:
https://smith.langchain.com/hub
ReAct Agent
https://arxiv.org/pdf/2210.03629.pdf
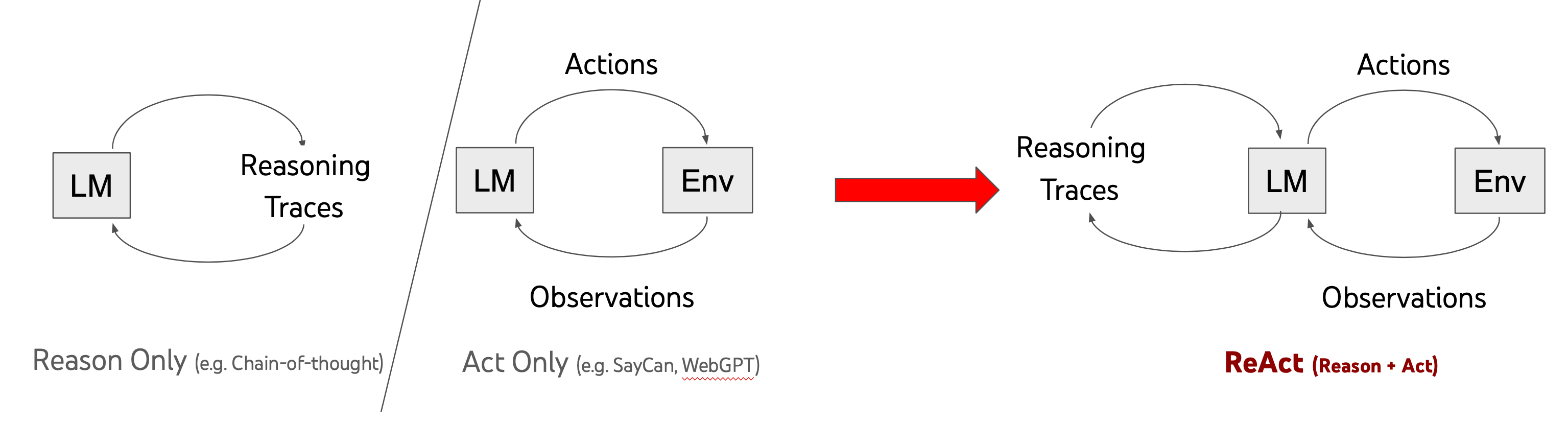
ReAct is inspired by the synergies between "acting" and "reasoning" which allow humans to learn new tasks and make decisions or reasoning.
Chain-of-thought (CoT) prompting has shown the capabilities of LLMs to carry out reasoning traces to generate answers to questions involving arithmetic and commonsense reasoning, among other tasks (Wei et al., 2022)(opens in a new tab). But it's lack of access to the external world or inability to update its knowledge can lead to issues like fact hallucination and error propagation.
ReAct is a general paradigm that combines reasoning and acting with LLMs. ReAct prompts LLMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while also enabling interaction to external environments (e.g., Wikipedia) to incorporate additional information into the reasoning. The figure below shows an example of ReAct and the different steps involved to perform question answering.
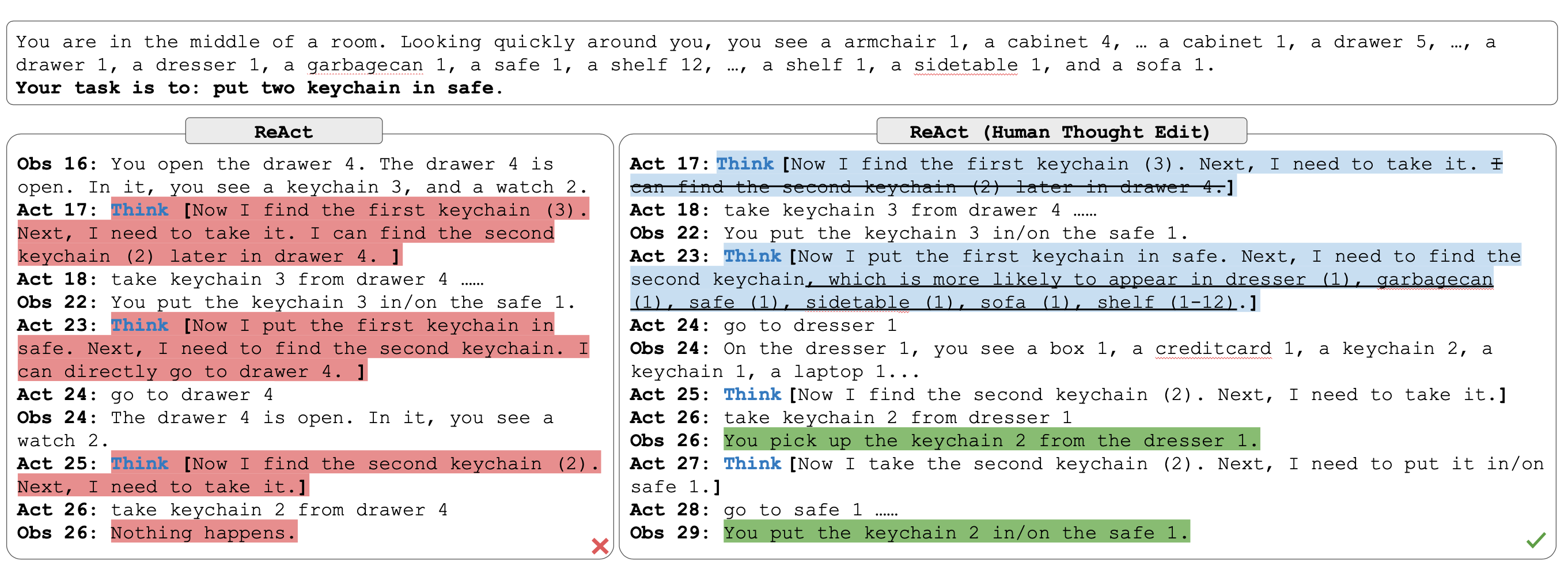
React Template in LangChain: https://smith.langchain.com/hub/hwchase17/react
React with Memory
https://smith.langchain.com/hub/hwchase17/react-chat
React Chat Agent
https://smith.langchain.com/hub/cpatrickalves/react-chat-agent
Self Ask with Search

Template in LangChain: https://smith.langchain.com/hub/hwchase17/self-ask-with-search
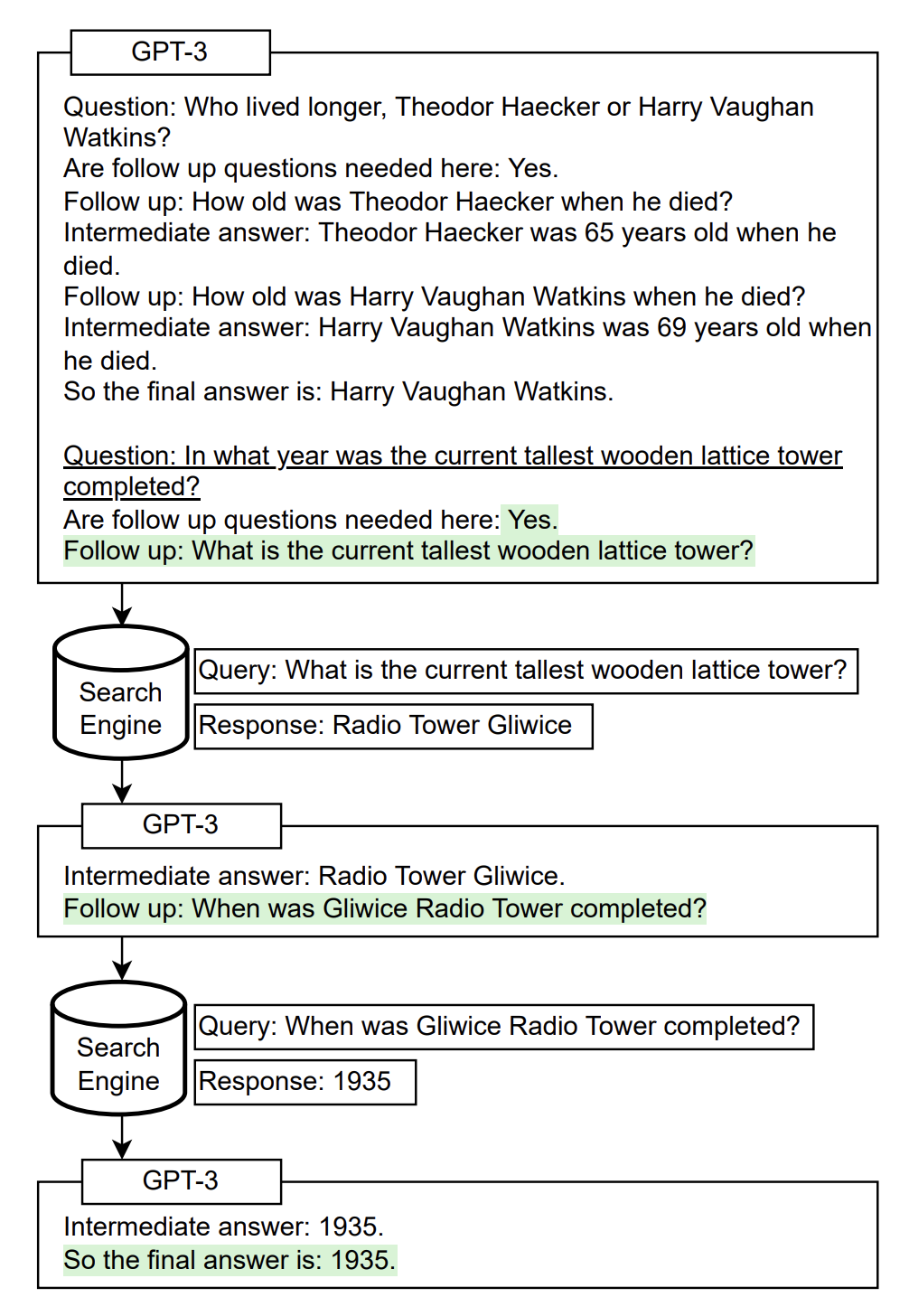
Let’s try to create simple tools to be used by a LLM
Here we will create a simple word length calculator function
import os
from langchain import hub
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent, tool
from langchain_openai import OpenAIos.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"We pull the “ReAct” template from the LangChain Hub of templates
prompt = hub.pull("hwchase17/react")promptPromptTemplate(input_variables=['agent_scratchpad', 'input', 'tool_names', 'tools'], template='Answer the following questions as best you can. You have access to the following tools:\n\n{tools}\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of \[\{tool_names\}\]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: {input}\nThought:{agent_scratchpad}')Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of tool_names
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: {agent_scratchpad}And then define the get_word_length function
@tool
def get_word_length(word: str) -> int:
"""Returns the length of the word."""
return len(word)tools = [get_word_length]We’ll use the Mixtral model from LocalAI
llm = ChatOpenAI(model="mixtral", streaming=False)Create the ReAct Agent using the tools and the prompt
agent = create_react_agent(llm, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)output = await agent_executor.ainvoke({"input": "how many letters in the word 'theschoolofai'?"})ubuntu-api-1 | get_word_length: get_word_length(word: str) -> int - Returns the length of the word.
ubuntu-api-1 |
ubuntu-api-1 | Use the following format:
ubuntu-api-1 |
ubuntu-api-1 | Question: the input question you must answer
ubuntu-api-1 | Thought: you should always think about what to do
ubuntu-api-1 | Action: the action to take, should be one of [get_word_length]
ubuntu-api-1 | Action Input: the input to the action
ubuntu-api-1 | Observation: the result of the action
ubuntu-api-1 | ... (this Thought/Action/Action Input/Observation can repeat N times)
ubuntu-api-1 | Thought: I now know the final answer
ubuntu-api-1 | Final Answer: the final answer to the original input question
ubuntu-api-1 |
ubuntu-api-1 | Begin!
ubuntu-api-1 |
ubuntu-api-1 | Question: how many letters in the word 'theschoolofai'?
ubuntu-api-1 | Thought:Action: get_word_length
ubuntu-api-1 | Action Input: 'theschoolofai'
ubuntu-api-1 | Observation: 15See, the llm wanted to use get_word_length function with input theschoolfoai and got the answer,
This is again sent to the model and the model concludes with “Final Answer” which stops the iterations
> Entering new AgentExecutor chain...
Action: get_word_length
Action Input: 'theschoolofai'15I now know the final answer.
Final Answer: The word 'theschoolofai' contains 15 letters.
> Finished chain.output{'input': "how many letters in the word 'theschoolofai'?",
'output': "The word 'theschoolofai' contains 15 letters."}Q&A Agent
We’ll do the same PDF QA we did in LLamaIndex but now with LangChain
pip install faiss-cpu pypdf! mkdir -p papers
! cd papers \
&& wget https://arxiv.org/pdf/2401.10166.pdf \
&& wget https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf \
&& wget https://arxiv.org/pdf/2401.07519v1.pdf \
&& wget https://arxiv.org/pdf/2212.11613v5.pdfimport os
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain.tools.retriever import create_retriever_tool
from langchain.chains import RetrievalQA
from langchain import hub
os.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"loader = PyPDFDirectoryLoader("papers/")docs = loader.load()text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)retriever = db.as_retriever()llm = OpenAI(model="mixtral", temperature=0)prompt = hub.pull("rlm/rag-prompt")qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)question = "What is VMamba? how is Mamba different from a Transformer?"
result = qa_chain.invoke({"query": question})result["result"]"VMamba is a novel architecture for visual representation learning, inspired by the state space model. It's different from a Transformer as it achieves linear complexity without sacrificing global receptive fields, unlike Transformers which have quadratic complexity. VMamba introduces the Cross-Scan Module to address the direction-sensitive issue in handling visual data, unlike the attention mechanism in Transformers."NOTE: Retrieval can be used as a tool as well!
Agent Chain with Search and Calculator
! pip install duckduckgo-search numexprimport os
from langchain.chains import LLMMathChain
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
from langchain_core.tools import Tool
from langchain_experimental.plan_and_execute import (
PlanAndExecute,
load_agent_executor,
load_chat_planner,
)
from langchain_openai import ChatOpenAI, OpenAI
os.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"search = DuckDuckGoSearchAPIWrapper()
llm = OpenAI(model="mixtral", temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math, but not date calculations, only math",
),
]model = ChatOpenAI(model="mixtral", temperature=0)
planner = load_chat_planner(model)
executor = load_agent_executor(model, tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor)Plan And Execute Agent
output = agent.invoke(
"Who is the current prime minister of the India? and what year was he born? if the year today is 2024?"
)Debug Logs
ubuntu-api-1 | ```
ubuntu-api-1 | $JSON_BLOB
ubuntu-api-1 | ```
ubuntu-api-1 | Observation: action result
ubuntu-api-1 | ... (repeat Thought/Action/Observation N times)
ubuntu-api-1 | Thought: I know what to respond
ubuntu-api-1 | Action:
ubuntu-api-1 | ```
ubuntu-api-1 | {
ubuntu-api-1 | "action": "Final Answer",
ubuntu-api-1 | "action_input": "Final response to human"
ubuntu-api-1 | }
ubuntu-api-1 | ```
ubuntu-api-1 |
ubuntu-api-1 | Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
ubuntu-api-1 | Thought:
ubuntu-api-1 | Previous steps: steps=[(Step(value='Find out the name of the current prime minister of India.'), StepResponse(response='The current prime minister of India is Narendra Modi.')), (Step(value='Find out the birth year of the current prime minister of India.'), StepResponse(response='Narendra Modi was born in 1950, specifically on September 17, 1950.')), (Step(value="Subtract the birth year from 2024 to determine the prime minister's current age."), StepResponse(response='The current Prime Minister of India, Narendra Modi, is 74 years old.'))]
ubuntu-api-1 |
ubuntu-api-1 | Current objective: value='Present the information in a coherent and concise manner.\n\n'
ubuntu-api-1 |
ubuntu-api-1 | [/INST]> Entering new AgentExecutor chain...
Thought: To answer this question, I need to find out who the current prime minister of India is. I can use the search tool to look up current information about the prime minister of India.
Action:
```json
{
"action": "Search",
"action_input": "current prime minister of India"
}Observation: The prime minister of India ... Modi is the 14th and current prime minister of India, serving since 26 May 2014. Origins and history. India follows a parliamentary system in which the prime minister is the presiding head of the government and chief of the executive of the government. India's Prime Minister Narendra Modi has hailed Monday's consecration ceremony as "the beginning of a new time cycle" in a speech to thousands of guests outside temple's complex. "Today our Lord ... Narendra Modi (born September 17, 1950, Vadnagar, India) Indian politician and government official who rose to become a senior leader of the Bharatiya Janata Party (BJP). In 2014 he led his party to victory in elections to the Lok Sabha (lower chamber of the Indian parliament), after which he was sworn in as prime minister of India.Prior to that he had served (2001-14) as chief minister ... Indian Prime Minister Narendra Modi will lead a ceremony on Monday to consecrate a grand new temple to the Hindu god-king Ram, delivering on a campaign promise his political party made more than ... Dec. 3, 2023. The ruling party of Prime Minister Narendra Modi has tightened its grip over India's populous northern belt, results of state elections showed Sunday, expanding its dominance of a ... Thought:Thought: The search result mentions Narendra Modi as the current prime minister of India. I will use the "Final Answer" tool to construct a response mentioning this.
Action:
{
"action": "Final Answer",
"action_input": "The current prime minister of India is Narendra Modi."
}
Finished chain.
Entering new AgentExecutor chain... Thought: To answer this question, I first need to find out the birth year of Narendra Modi, the current prime minister of India.
Action:
{
"action": "Search",
"action_input": "Birth year of Narendra Modi"
}
Observation: Narendra Modi (born September 17, 1950, Vadnagar, India) Indian politician and government official who rose to become a senior leader of the Bharatiya Janata Party (BJP). Ornate gifts have started arriving in the Indian city of Ayodhya as the country's Prime Minister Narendra Modi prepares to inaugurate a vast Hindu temple that he hopes will firm his chances for ... Who is Narendra Modi - Know about Narendra Modi Profile and brief Biography with factsheet. ... Narendra Damodardas Modi; DOB: Sept 17, 1950: Place of Birth: Vadnagar, Mehsana, Gujarat: Religion: Hindu: ... First bilateral visit by an Indian Prime Minister in 28 years. Modi attended the G-20 Summit in Brisbane which was followed by a state ... Prime Minister Narendra Modi is celebrating his 73rd birthday on September 17, 2023. He was born in Vadnagar, Gujarat. Let's take a look at how he has celebrated his birthday in the last couple ... Primary Education: Narendra Modi was born on September 17, 1950, in Vadnagar, a small town in Gujarat, India. He completed his primary education in Vadnagar. Higher Secondary Education: He completed his higher secondary education at a school in Vadnagar. Thought:Action:
{
"action": "Final Answer",
"action_input": "Narendra Modi was born in 1950, specifically on September 17, 1950."
}
Finished chain.
Entering new AgentExecutor chain... Thought: To find the current age of the Prime Minister, I need to subtract his birth year from the current year, 2024. I can use the calculator tool for this task.
Action:
{
"action": "Calculator",
"action_input": "2024 - 1950"
}
Entering new LLMMathChain chain... 2024 - 1950```text 2024 - 1950
...numexpr.evaluate("2024 - 1950")...
Answer: 74
> Finished chain.
Observation: Answer: 74
Thought:To find the current age of the Prime Minister, I need to subtract his birth year from the current year, 2024. I can use the calculator tool for this task.
Action:
```json
{
"action": "Calculator",
"action_input": "2024 - 1950"
}
Entering new LLMMathChain chain... 2024 - 1950```text 2024 - 1950
...numexpr.evaluate("2024 - 1950")...
Answer: 74
> Finished chain.
Observation: Answer: 74
Thought:To find the current age of the Prime Minister, I need to subtract his birth year from the current year, 2024. I can use the calculator tool for this task.
Action:
```json
{
"action": "Calculator",
"action_input": "2024 - 1950"
}
Entering new LLMMathChain chain... 2024 - 1950```text 2024 - 1950
...numexpr.evaluate("2024 - 1950")...
Answer: 74
> Finished chain.
Observation: Answer: 74
Thought:Thought: The calculator tool has been used three times to subtract the birth year of the Prime Minister (1950) from the current year (2024). Each time, the result has been 74. Therefore, I can confidently say that the Prime Minister is currently 74 years old.
Action:
```json
{
"action": "Final Answer",
"action_input": "The current Prime Minister of India, Narendra Modi, is 74 years old."
}
Finished chain.
Entering new AgentExecutor chain... Action:
{
"action": "Final Answer",
"action_input": "The current prime minister of India is Narendra Modi, who was born in 1950. Therefore, he is currently 74 years old."
}Finished chain.
```python
output
{'input': 'Who is the current prime minister of the India? and what year was he born? if the year today is 2024?',
'output': 'The current prime minister of India is Narendra Modi, who was born in 1950. Therefore, he is currently 74 years old.'}Agent with Coding Skills!
Here we simply give it the Python REPL Tool
from langchain import hub
from langchain.agents import AgentExecutor
from langchain_experimental.tools import PythonREPLTool
import os
os.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"tools = [PythonREPLTool()]from langchain.agents import create_react_agentinstructions = """You are an agent designed to write and execute python code to answer questions.
You have access to a python REPL, which you can use to execute python code.
If you get an error, debug your code and try again.
Only use the output of your code to answer the question.
You might know the answer without running any code, but you should still run the code to get the answer.
If it does not seem like you can write code to answer the question, just return "I don't know" as the answer.
"""
base_prompt = hub.pull("langchain-ai/react-agent-template")
prompt = base_prompt.partial(instructions=instructions)print(base_prompt.template){instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
Thought: Do I need to use a tool? Yes Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action Observation: the result of the action
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
Thought: Do I need to use a tool? No Final Answer: [your response here]
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}
agent = create_react_agent(ChatOpenAI(model="mixtral", temperature=0), tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)await agent_executor.ainvoke({"input": "What is the 10th fibonacci number?"})> Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: Python_REPL
Action Input: def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
print(fibonacci(10))55
Do I need to use a tool? No
Final Answer: The 10th Fibonacci number is 55.
> Finished chain.
{'input': 'What is the 10th fibonacci number?',
'output': 'The 10th Fibonacci number is 55.'}Okay, let’s try a Project Euler Problem
https://projecteuler.net/problem=14
await agent_executor.ainvoke({
"input": """<p>The following iterative sequence is defined for the set of positive integers:</p>
<ul style="list-style-type:none;">
<li>$n \to n/2$ ($n$ is even)</li>
<li>$n \to 3n + 1$ ($n$ is odd)</li></ul>
<p>Using the rule above and starting with $13$, we generate the following sequence:
$$13 \to 40 \to 20 \to 10 \to 5 \to 16 \to 8 \to 4 \to 2 \to 1.$$</p>
<p>It can be seen that this sequence (starting at $13$ and finishing at $1$) contains $10$ terms. Although it has not been proved yet (Collatz Problem), it is thought that all starting numbers finish at $1$.</p>
<p>Which starting number, under one million, produces the longest chain?</p>
<p class="note"><b>NOTE:</b> Once the chain starts the terms are allowed to go above one million.</p>
</p>
"""
})> Entering new AgentExecutor chain...
Python REPL can execute arbitrary code. Use with caution.
Thought: Do I need to use a tool? Yes
Action: Python_REPL
Action Input:
```python
def collatz(n):
steps = 0
while n != 1:
if n % 2 == 0:
n = n // 2
else:
n = 3*n + 1
steps += 1
return steps
max_steps = 0
max_number = 0
for i in range(1, 1000000):
num_steps = collatz(i)
if num_steps > max_steps:
max_steps = num_steps
max_number = i
print(max_number)
```837799
Do I need to use a tool? No
Final Answer: The starting number under one million that produces the longest chain is 837799.837799 that’s right!
Agent with Google Search & Memory
Get Google Search API Key From
https://developers.google.com/custom-search/v1/introduction
Create CSE
https://programmablesearchengine.google.com/controlpanel/create
! pip install google-api-python-clientimport os
from langchain.agents import AgentExecutor, Tool, ZeroShotAgent
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import SQLChatMessageHistory
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import OpenAI
os.environ["OPENAI_API_BASE"] = "http://localhost:8080/v1"
os.environ["OPENAI_API_KEY"] = "NONE"
os.environ["GOOGLE_API_KEY"] = "i-dontknow"
os.environ["GOOGLE_CSE_ID"] = "maybe-ai-knows?"search = GoogleSearchAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
)
]prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)Zero Shot Agent
Zero-shot means the agent functions on the current action only — it has no memory. It uses the ReAct framework to decide which tool to use, based solely on the tool’s description.
message_history = SQLChatMessageHistory(
session_id="test_session_id", connection_string="sqlite:///sqlite.db"
)
memory = ConversationBufferMemory(
memory_key="chat_history", chat_memory=message_history
)llm_chain = LLMChain(llm=OpenAI(model="mixtral", temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=True, memory=memory
)agent_chain.run(input="How many people live in india?")> Entering new AgentExecutor chain...
Thought: I don't have this information readily available, I will need to search for the current population of India.
Action: Search
Action Input: Current population of India
Observation: The current population of India is 1,435,983,120 as of Tuesday, January 23, 2024, based on Worldometer elaboration of the latest United Nations data 1. · India ... World Population ; 1. China · 2. India · 3. United States ; 1,416,043,270 · 1,409,128,296 · 336,673,595 ; 6. Nigeria · 7. Brazil · 8. Bangladesh ... Apr 24, 2023 ... Current population trends in China and India are determined largely by fertility levels since the 1970s. In 1971, China and India had nearly ... Last November, the global population reached a significant milestone of 8 billion. More recently, in April, India overtook China as the world's most populous ... Apr 24, 2023 ... By the end of this month, India's population is expected to reach 1,425,775,850 people, matching and then surpassing the population of mainland ... growth that is embedded in the youthful age structure of the current population. ... China and India accounted for the largest populations in these regions, with. total: 4.5% of population (2020 est.) Current health expenditure. 3% of GDP (2020). Physicians density. 0.74 physicians/1,000 population (2020) ... Sep 21, 2021 ... In the most recent decade between censuses, Hindus added 138 million (13.8 crore) people, while Muslims grew by 34 million (3.4 crore). India's ... Per cent of population below poverty line: 22% (2006 est.) Unemployment rate: 7.8%. Net migration rate: 0.00 migrant(s)/ ... Apr 20, 2023 ... NEW DELHI, April 19 (Reuters) - India is poised to overtake China as the world's most populous nation, with almost 3 million more people ...
Thought:I have found information about India's current population.
Final Answer: As of my last search on January 23, 2024, the current population of India is 1,435,983,120 people.
> Finished chain.
'As of my last search on January 23, 2024, the current population of India is 1,435,983,120 people.'agent_chain.run(input="who wrote their national anthem?")> Entering new AgentExecutor chain...
Thought: I don't have this information readily available, I will need to search for the answer.
Action: Search
Action Input: who wrote India's national anthem?
Observation: The National Anthem of India is titled "Jana Gana Mana". The song was originally composed in Bengali by India's first Nobel laureate Rabindranath Tagore on 11 ... On February 28th, 1919, Tagore wrote down an English interpretation of the full Bengali song, and titled it 'The Morning Song of India'. This was requested ... The first two verses of the poem were adopted as the National Song of India in October 1937 by the Congress. Vande Mataram. Vande Mataram written ... National Anthem. The song Jana-gana-mana, composed originally in Bangla by Rabindranath Tagore, was adopted in its Hindi version by the Constituent ... Sep 15, 2023 ... Both words and music were written in 1911 by India's first Nobel laureate, Rabindranath Tagore. Tagore's original version, titled 'Bharoto ... Thou art the ruler of the minds of all people, Thou Dispenser of India's destiny. Thy name rouses the hearts of Punjab, Sind, Gujrat and Maratha, Of Dravid, ... Jana Gana Mana is our National Anthem. It was originally composed in Bengali by Rabindranath Tagore and was later adopted as our National Anthem on 24 January ... Jul 14, 2023 ... We Indians are aware of our National Anthem - 'Jana Gana Mana' and National Song - 'Vande Mataram'. But when it comes to referring to them ... Jul 11, 2019 ... From Bombay to Baltimore: Was the American national anthem composed on a ship built in India at the Wadia Shipyard? · The Star-Spangled Banner – ... Dec 6, 2016 ... “Jana Gana Mana Adhinayaka,” which was loosely translated as “the leader of people's minds” by Amartya Sen was alleged to have been composed for ...
Thought:I now know the final answer
Final Answer: The National Anthem of India, "Jana Gana Mana", was written by Rabindranath Tagore.
> Finished chain.
'The National Anthem of India, "Jana Gana Mana", was written by Rabindranath Tagore.'GPTs
OpenGPTs: https://github.com/langchain-ai/opengpts
Langchain Integrations: https://python.langchain.com/docs/integrations/providers
Towards AGI

It started with this: https://x.com/yoheinakajima/status/1640934493489070080?s=20
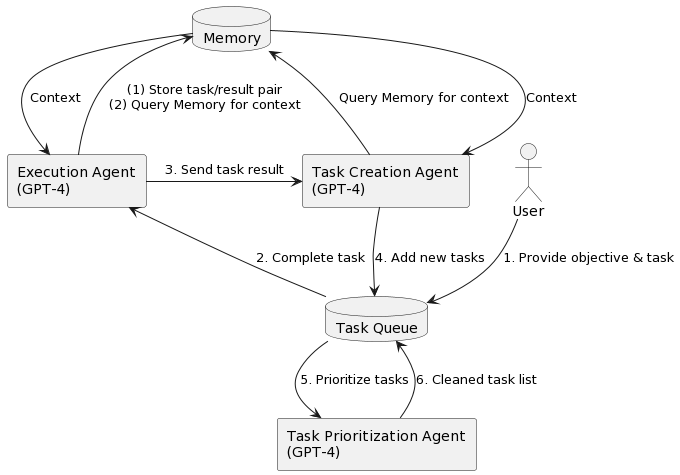
The system runs on an infinite loop and is executed using 4 steps:
- The first task is pulled from the task list
- The task is sent to the execution agent and completes the task, based on context using OpenAI API
- The result is stored into Pinecone
- New tasks are created and prioritized based on the objective and the result of the previous task.
The OG BabyAGI Code
# *********HOW TO USE**********
# 1. Fork this into a private Repl
# 2. Add your OpenAI API Key and Pinecone API Key
# 3. Go to "Shell" (over to the right ->) and type "pip install pinecone-client" and press enter
# 4. Update the OBJECTIVE variable
# 5. Press "Run" at the top.
# NOTE: the first time you run, it will initiate the table first - which may take a few minutes, you'll be waiting at the initial OBJECTIVE phase. If it fails, try again.)
#
# WARNING: THIS CODE WILL KEEP RUNNING UNTIL YOU STOP IT. BE MINDFUL OF OPENAI API BILLS. DELETE PINECONE INDEX AFTER USE.
import openai
import pinecone
import time
from collections import deque
from typing import Dict, List
#Set API Keys
OPENAI_API_KEY = ""
PINECONE_API_KEY = ""
PINECONE_ENVIRONMENT = "us-east1-gcp" #Pinecone Environment (eg. "us-east1-gcp")
#Set Variables
YOUR_TABLE_NAME = "test-table"
OBJECTIVE = "Solve world hunger."
YOUR_FIRST_TASK = "Develop a task list."
#Print OBJECTIVE
print("\033[96m\033[1m"+"\n*****OBJECTIVE*****\n"+"\033[0m\033[0m")
print(OBJECTIVE)
# Configure OpenAI and Pinecone
openai.api_key = OPENAI_API_KEY
pinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_ENVIRONMENT)
# Create Pinecone index
table_name = YOUR_TABLE_NAME
dimension = 1536
metric = "cosine"
pod_type = "p1"
if table_name not in pinecone.list_indexes():
pinecone.create_index(table_name, dimension=dimension, metric=metric, pod_type=pod_type)
# Connect to the index
index = pinecone.Index(table_name)
# Task list
task_list = deque([])
def add_task(task: Dict):
task_list.append(task)
def get_ada_embedding(text):
text = text.replace("\n", " ")
return openai.Embedding.create(input=[text], model="text-embedding-ada-002")["data"][0]["embedding"]
def task_creation_agent(objective: str, result: Dict, task_description: str, task_list: List[str]):
prompt = f"You are an task creation AI that uses the result of an execution agent to create new tasks with the following objective: {objective}, The last completed task has the result: {result}. This result was based on this task description: {task_description}. These are incomplete tasks: {', '.join(task_list)}. Based on the result, create new tasks to be completed by the AI system that do not overlap with incomplete tasks. Return the tasks as an array."
response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,temperature=0.5,max_tokens=100,top_p=1,frequency_penalty=0,presence_penalty=0)
new_tasks = response.choices[0].text.strip().split('\n')
return [{"task_name": task_name} for task_name in new_tasks]
def prioritization_agent(this_task_id:int):
global task_list
task_names = [t["task_name"] for t in task_list]
next_task_id = int(this_task_id)+1
prompt = f"""You are an task prioritization AI tasked with cleaning the formatting of and reprioritizing the following tasks: {task_names}. Consider the ultimate objective of your team:{OBJECTIVE}. Do not remove any tasks. Return the result as a numbered list, like:
#. First task
#. Second task
Start the task list with number {next_task_id}."""
response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,temperature=0.5,max_tokens=1000,top_p=1,frequency_penalty=0,presence_penalty=0)
new_tasks = response.choices[0].text.strip().split('\n')
task_list = deque()
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = task_parts[0].strip()
task_name = task_parts[1].strip()
task_list.append({"task_id": task_id, "task_name": task_name})
def execution_agent(objective:str,task: str) -> str:
context=context_agent(index=YOUR_TABLE_NAME, query=objective, n=5)
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f"You are an AI who performs one task based on the following objective: {objective}. Your task: {task}\nResponse:",
temperature=0.7,
max_tokens=2000,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0].text.strip()
def context_agent(query: str, index: str, n: int):
query_embedding = get_ada_embedding(query)
index = pinecone.Index(index_name=index)
results = index.query(query_embedding, top_k=n,
include_metadata=True)
#print("***** RESULTS *****")
#print(results)
sorted_results = sorted(results.matches, key=lambda x: x.score, reverse=True)
return [(str(item.metadata['task'])) for item in sorted_results]
# Add the first task
first_task = {
"task_id": 1,
"task_name": YOUR_FIRST_TASK
}
add_task(first_task)
# Main loop
task_id_counter = 1
while True:
if task_list:
# Print the task list
print("\033[95m\033[1m"+"\n*****TASK LIST*****\n"+"\033[0m\033[0m")
for t in task_list:
print(str(t['task_id'])+": "+t['task_name'])
# Step 1: Pull the first task
task = task_list.popleft()
print("\033[92m\033[1m"+"\n*****NEXT TASK*****\n"+"\033[0m\033[0m")
print(str(task['task_id'])+": "+task['task_name'])
# Send to execution function to complete the task based on the context
result = execution_agent(OBJECTIVE,task["task_name"])
this_task_id = int(task["task_id"])
print("\033[93m\033[1m"+"\n*****TASK RESULT*****\n"+"\033[0m\033[0m")
print(result)
# Step 2: Enrich result and store in Pinecone
enriched_result = {'data': result} # This is where you should enrich the result if needed
result_id = f"result_{task['task_id']}"
vector = enriched_result['data'] # extract the actual result from the dictionary
index.upsert([(result_id, get_ada_embedding(vector),{"task":task['task_name'],"result":result})])
# Step 3: Create new tasks and reprioritize task list
new_tasks = task_creation_agent(OBJECTIVE,enriched_result, task["task_name"], [t["task_name"] for t in task_list])
for new_task in new_tasks:
task_id_counter += 1
new_task.update({"task_id": task_id_counter})
add_task(new_task)
prioritization_agent(this_task_id)
time.sleep(1) # Sleep before checking the task list againbabyagi: https://github.com/yoheinakajima/babyagi/blob/main/babyagi.py
BabyCatAGI: https://github.com/yoheinakajima/babyagi/blob/main/classic/BabyCatAGI.py
BabyCoder: https://github.com/yoheinakajima/babyagi/blob/main/babycoder/README.md
https://github.com/reworkd/AgentGPT?tab=readme-ov-file#-demo
https://github.com/mudler/LocalAGI/tree/main#demo
NOTES
- LocalAGI: https://github.com/mudler/LocalAGI
- BabyAGI: https://github.com/yoheinakajima/babyagi
- SuperAGI: https://github.com/TransformerOptimus/SuperAGI
- AgentGPT: https://github.com/reworkd/AgentGPT
- Open Interpreter: https://github.com/KillianLucas/open-interpreter
- AutoGPT LangChain: https://github.com/langchain-ai/langchain/blob/master/cookbook/autogpt/autogpt.ipynb
- https://cookbook.openai.com/examples/how_to_call_functions_with_chat_models
- WebScraping with LangChain: https://python.langchain.com/docs/use_cases/web_scraping
- LangChain RAG: https://docs.smith.langchain.com/cookbook/hub-examples/retrieval-qa-chain
- Sudoku Solver with Tree of Thought: https://github.com/langchain-ai/langchain/blob/master/cookbook/tree_of_thought.ipynb
- LangServe: https://python.langchain.com/docs/langserve
- https://python.langchain.com/docs/langserve#playground
- Analyze Document: https://github.com/langchain-ai/langchain/blob/master/cookbook/analyze_document.ipynb
- SQL Agent: https://python.langchain.com/docs/integrations/toolkits/sql_database
- https://www.promptingguide.ai/
- Examples of Prompting: https://www.promptingguide.ai/introduction/examples
- https://github.com/kwaikeg/kwaiagents
- https://docs.llamaindex.ai/en/stable/understanding/putting_it_all_together/chatbots/building_a_chatbot.html
- https://github.com/joaomdmoura/crewAI